
Einführung der Technologie, kritischer Sprache und Risiken.
Künstliche Intelligenz (KI) schleicht sich jetzt in unser tägliches Leben ein, vor allem das Leben derer, die viel Zeit online verbringen. Aber was ist das? Jede neue Technologie birgt Vor- und Nachteile, Nachteile und Risiken. Was macht KI anders?
Wir hören dunkles Murren über eine Zukunft, die mit KI und KI-betriebenen Robotern zusammenlebt, verschiedene Darstellungen in Videomedien (“Matrix”, der visionäre Spike Jonze-Film Her“Her”, die Terminator“Terminator”-Serie und so viele andere) und lesen über Neuralink, die Bewunderung des Weltwirtschaftsforums für eine dunkle transmenschliche Zukunft – die vierte Industrial-Revolution und die Vierte Industrielle Revolution.Selbst, dass die Menschen obsolet sind und durch Maschinen ersetzt werden müssen, die verantwortlichere Verwalter sowohl der Erde als auch der Zukunft sein werden.
Diejenigen, die diesen Substack und meine verschiedenen Vorträge und Podcasts verfolgen, haben vielleicht bemerkt, dass ich beginne, die vielen ethischen Probleme zu erforschen, die mit künstlicher Intelligenz (KI) und den Schnittstellen zwischen Mensch und KI verbunden sind. Ich interessiere mich besonders für die Schnittstellen von PsyWar und KI, Mensch/Transhumanismus und KI, österreichische Schulwirtschaftstheorie und KI sowie Korporatismus/Globalismus/Globalregierung und KI. Wie viele andere habe ich ein vages Verständnis dessen, was gemeinhin als KI bezeichnet wird, aber ich brauche mehr Tiefe und Expertise, um die Auswirkungen und die Ethik zu verstehen, die mit dieser Technologie verbunden sind.
Sind diese Themen zu weit „über meine Spur“? Was ist mein relevanter Hintergrund und Erfahrung? Warum sollten Sie, der Leser, auf dieser Erkundungsreise mitreisen wollen?
Von 1980 bis 1982 war ich Informatikstudent, der in Computerarchitektur und Programmier- (Codierung) Grundlagen geschult wurde, einschließlich einer Handvoll Programmiersprachen – einige wurden noch verwendet. Während der frühen Jahre der COVID-Krise habe ich eng mit einem hochqualifizierten und erfahrenen Informatiker zusammengearbeitet, der bei MIT Lincoln Laboratories angestellt ist (konzentriert auf die Wiederverwendung von Medikamenten zur COVID-Behandlung), und er trainierte mich auf die Grundlagen der künstlichen Intelligenz. In jüngerer Zeit habe ich ein paar Jahre in die Entwicklung eines fortgeschrittenen Verständnisses von PsyWar, Transhumanismus und Globalismus investiert. Ich habe einen soliden Hintergrund in der Bioethik und Erfahrung aus erster Hand mit den Kulturen und ethischen Fragen, die sich in der innovativen, innovativen technischen Forschung und Anwendungsentwicklung ergeben. Ich bin geschickt darin, technische Informationen zu überprüfen, zu synthetisieren und zu zusammenfassen. Ich möchte verstehen, wie sich KI auf mein Leben und meine Umgebung auswirken wird, damit ich mehr auf die Zukunft vorbereitet sein und einige Risiken mindern kann.
Das ist das Toolkit, das ich mit den Themen anspriche. Wenn Sie die resultierenden Essays mitführen möchten, können wir dann entscheiden, ob das genug ist.
Beginnen wir mit der Definition einiger Schlüsselbegriffe und Konzepte.
Was ist „Künstliche Intelligenz“
Künstliche Intelligenz (KI) bezieht sich auf Computersysteme oder Algorithmen, die intelligentes menschliches Verhalten nachahmen. Es ermöglicht Maschinen:
- Vernunft und Entscheidungen treffen
- Entdecken Sie Muster und Beziehungen in Daten
- Allgemein und Apping Wissen auf neue Situationen
- Lernen Sie aus vergangenen Erfahrungen und passen Sie sich neuen Informationen an
KI-Systeme werden durch die Verarbeitung von großen Datenmengen entwickelt, um Muster zu identifizieren, Entscheidungsfindung zu modellieren und Ergebnisse wie Vorhersagen, Empfehlungen oder Entscheidungen zu generieren. Diese Fähigkeit wurde zum Teil durch das Studium der Muster des menschlichen Gehirns und die Analyse kognitiver Prozesse erreicht. Die aktuelle Generation der „engen“ KI hat jedoch mehr mit vergleichender Datenset-Analyse („Maschinelles Lernen“ oder „Deep Learning“) zu tun als mit fortschrittlichen Konzepten, die eine neuronale Netzwerkmodellierung des menschlichen Gehirns und der Kognition beinhalten, obwohl aktuelle Konzepte in der Humanneurobiologie angewendet werden, um die Entwicklung fortschrittlicher künstlicher Intelligenzfähigkeiten zu informieren.
Sie fragen sich vielleicht, ob computerbasierte KI Bewusstsein oder Empfindungsfähigkeit erreichen kann. Wenn ja, werden Sie diesen Essay lesen, der in Psychology Today von Arzt Robert Lanza veröffentlicht wurde, einem der führenden Befürworter des aufkommenden Gedankenraums, der als „Biozentrismus“ bekannt ist.
Eckaspekte der KI:
- Nachahmung menschlicher Intelligenz: KI-Systeme simulieren menschenähnliches Denken und Verhalten.
- Computergesteuert: KI wird von Software oder Algorithmen ausgeführt, die auf Computern oder Robotern laufen.
- Autonome Entscheidungsfindung : KI-Systeme treffen Entscheidungen auf Basis ihrer Programmierung und Datenanalyse.
Ist KI dasselbe wie maschinelles Lernen?
Maschinelles Lernen (und Deep Learning) sind Methoden, die entwickelt wurden, um einen Computer auszubilden, um von seinen Eingaben zu lernen, ohne für jeden Umstand explizit zu programmieren. Mit Maschinen- und Deep-Learning kann auch ein digitales Rechensystem trainiert werden, um eine enge künstliche Intelligenz zu erreichen.
Was ist maschinelles Lernen?
Maschinelles Lernen beinhaltet die vergleichende Verarbeitung großer Datensätze zur Erkennung von Mustern, Assoziationen und Beziehungen. Die resultierenden Informationen werden verwendet, um verschiedene Zusammenfassungen, Empfehlungen oder Vorhersagen zu allgemeinen Phänomenen zu generieren.

Sara Brown, die für die MIT Sloan School of Management schreibt, erklärt;
Maschinelles Lernen beginnt mit Daten – Zahlen, Fotos oder Texten, wie Banktransaktionen, Bilder von Personen oder sogar Backwaren, Reparaturaufzeichnungen, Zeitreihendaten von Sensoren oder Verkaufsberichten. Die Daten werden gesammelt und als Schulungsdaten oder die Informationen des maschinellen Lernmodells erstellt. Je mehr Daten, desto besser das Programm.
Von dort wählen Programmierer ein Modell für maschinelles Lernen, um die Daten zu verwenden, zu liefern und das Computermodell selbst trainieren zu lassen, um Muster zu finden oder Vorhersagen zu treffen. Im Laufe der Zeit kann der menschliche Programmierer auch das Modell optimieren, einschließlich der Änderung seiner Parameter, um es zu genaueren Ergebnissen zu bringen. (Die Website der Forscherin Janelle Shane, AI Weirdness, ist ein unterhaltsamer Blick darauf, wie Algorithmen des maschinellen Lernens lernen und wie sie die Dinge falsch machen können – wie es passiert ist, als ein Algorithmus versuchte, Rezepte zu generieren und Chocolate Chicken Chicken Cake zu erstellen.)
Der Prozess beinhaltet die Entwicklung eines großen Datensatzes, die Aufteilung dieser Daten in zwei oder mehr Gruppen (Trainings- und Validierungssätze), die Analyse eines Datensatzes für Muster und Vorhersagen, um ein Modell der zugrunde liegenden Realität zu erstellen, die vom Trainingsset bemustert wird, und zu testen, ob diese Muster und Vorhersagen, die aus dem Trainingssatz abgeleitet sind, wenn sie auf das Validierungs-Set(n) angewendet werden, und das “Revegnieren”.
Rückkehr zu Sarah Brown;
Es gibt drei Unterkategorien des maschinellen Lernens:
Überwachte Modelle des maschinellen Lernens werden mit beschrifteten Datensätzen geschult, die es den Modellen ermöglichen, im Laufe der Zeit genauer zu lernen und zu wachsen. Zum Beispiel würde ein Algorithmus mit Bildern von Hunden und anderen Dingen trainiert, die alle von Menschen beschriftet sind, und die Maschine würde Wege lernen, Bilder von Hunden allein zu identifizieren. Überwachtes maschinelles Lernen ist der häufigste Typ, der heute verwendet wird.
Bei unbeaufsichtigten maschinellen Lernen sucht ein Programm nach Mustern in unbeschrifteten Daten. Unüberwachtes maschinelles Lernen kann Muster oder Trends finden, die Menschen nicht explizit suchen. Zum Beispiel könnte ein unbeaufsichtigtes maschinelles Lernprogramm durch Online-Verkaufsdaten suchen und verschiedene Arten von Kunden identifizieren, die Einkäufe tätigen.
Reinforcement Verstärkungsmaschinenlernen schult Maschinen durch Versuch und Irrtum, um die besten Maßnahmen zu ergreifen, indem ein Belohnungssystem eingerichtet wird. Das Bewehrlernen kann Modelle trainieren, um Spiele zu spielen oder autonome Fahrzeuge zu trainieren, indem sie der Maschine sagt, wenn sie die richtigen Entscheidungen getroffen hat, was ihr hilft, im Laufe der Zeit zu lernen, welche Maßnahmen sie ergreifen sollte.
Brown erklärt, dass maschinelles Lernen auch mit mehreren anderen Teilfeldern der künstlichen Intelligenz in Verbindung gebracht wird:
Natürliche Sprachverarbeitung
Die Verarbeitung natürlicher Sprache ist ein Bereich des maschinellen Lernens, in dem Maschinen lernen, die natürliche Sprache zu verstehen, wie sie vom Menschen gesprochen und geschrieben wurde, anstelle der Daten und Nummern, die normalerweise zur Programmierung von Computern verwendet werden. Dies ermöglicht es Maschinen, Sprache zu erkennen, zu verstehen und darauf zu reagieren sowie neuen Text zu erstellen und zwischen den Sprachen zu übersetzen. Die Verarbeitung natürlicher Sprache ermöglicht vertraute Technologien wie Chatbots und digitale Assistenten wie Siri oder Alexa.
Neuralnetze
Neuralnetzwerke sind eine häufig verwendete, spezifische Klasse von Algorithmen des maschinellen Lernens. Künstliche neuronale Netze sind dem menschlichen Gehirn nachempfunden, in dem Tausende oder Millionen von Verarbeitungknoten miteinander verbunden und zu Schichten organisiert werden.
In einem künstlichen neuronalen Netzwerk sind Zellen oder Knoten miteinander verbunden, wobei jede Zellverarbeitung eingeschalteter Input und eine Ausgabe produziert, die an andere Neuronen gesendet wird. Beschriftete Daten bewegen sich durch die Knoten oder Zellen, wobei jede Zelle eine andere Funktion ausführt. In einem neuronalen Netzwerk, das darauf trainiert ist, zu identifizieren, ob ein Bild eine Katze enthält oder nicht, würden die verschiedenen Knoten die Informationen bewerten und zu einem Ausgang gelangen, der anzeigt, ob ein Bild eine Katze zeigt.
Deep Learning
Deep-Learning-Netzwerke sind neuronale Netze mit vielen Schichten. Das geschichtete Netzwerk kann umfangreiche Datenmengen verarbeiten und das “Gewicht” jedes Links im Netzwerk bestimmen – zum Beispiel in einem Bilderkennungssystem könnten einige Schichten des neuronalen Netzwerks einzelne Gesichtsmerkmale wie Augen, Nase oder Mund erkennen, während eine andere Schicht in der Lage wäre zu sagen, ob diese Merkmale in einem Gesicht angezeigt werden.
Wie neuronale Netzwerke ist Deep Learning der Art und Weise nachempfunden, wie das menschliche Gehirn funktioniert und viele maschinelle Lernnutzungen wie autonome Fahrzeuge, Chatbots und medizinische Diagnostik anmacht.
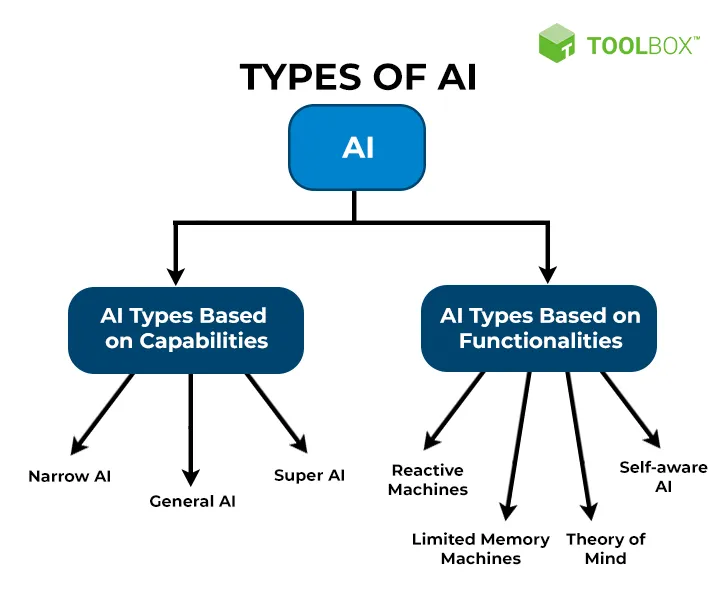
Verschiedene Kategorien der Künstlichen Intelligenz: Narrow, General und Super AI
Um diese Frage zu beantworten, habe ich aus einem Artikel von V.K. Anirudh für die Website Spiceworks.com.
Enge Künstliche Intelligenz
Narrow AI ist heute die häufigste Art von KI und findet sich in einer Vielzahl von Mobiltelefonanwendungen, Internet-Suchmaschinen und Big-Data-Analysen. Die meisten der KI, auf die Sie derzeit stoßen oder verwenden, sind schmale KI.
Der Name rührt daher, dass diese Systeme der künstlichen Intelligenz explizit für eine einzige Aufgabe geschaffen werden. Aufgrund dieses engen Ansatzes und der Unfähigkeit, andere Aufgaben als die zu erfüllen, die ihnen angegeben sind, werden sie auch „schwache“ KI genannt. Damit wird ihre „Intelligenz“ sehr auf eine Aufgabe oder Aufgaben ausgerichtet, was eine weitere Optimierung und Optimierung ermöglicht. Da sich diese Systeme auf die ihnen zugewiesenen Aufgaben beschränken, sind sie auch als “schwache” KI bekannt.
Schmale KI wird mit aktuellen Standards und Tools erstellt
Mit der Zunahme der Einführung von KI durch Unternehmen wird erwartet, dass die Technologie eine Sache gut macht. Narrow AI wird in einer Umgebung entwickelt, in der das Problem mit der neuesten Technologie im Mittelpunkt steht.
Dank seiner hohen Effizienz-, Geschwindigkeits- und menschlichen Konsumrate ist eine enge künstliche Intelligenz zu einer der wichtigsten Lösungen vieler Unternehmen geworden. Für verschiedene Low-Level-Aufgaben kann enge KI intelligente Automatisierung und Integration einsetzen, um Effizienz bei gleichzeitiger Aufrechterhaltung der Genauigkeit zu gewährleisten.
Dies macht es zu einer bevorzugten Wahl für Aufgaben, die Millionen von Datenmengen beinhalten, die als Big Data bekannt sind. Mit der vorherrschenden Sammlung persönlicher Daten (siehe Überwachungskapitalismus und PsyWar) verfügen Unternehmen über eine große Menge an Big Data, die zur Ausbildung von KI und Erkenntnissen verwendet werden kann.
Arten der Künstlichen Intelligenz
Um zwischen dem Grad zu unterscheiden, in dem KI-Anwendungen Aufgaben ausführen können, sind sie in der Regel in drei Typen aufgeteilt. Diese Typen unterscheiden sich voneinander und zeigen heute die natürliche Entwicklung zu KI-Systemen.
Enge Künstliche Intelligenz
Schmale KI ist heute die häufigste Art von KI. Von Anwendungen in Mobiltelefonen über das Internet bis hin zur Big-Data-Analyse nimmt enge KI die Welt im Sturm.
Der Name rührt daher, dass diese Art von künstlichen Intelligenzsystemen explizit für eine einzige Aufgabe geschaffen wird. Aufgrund dieses engen Ansatzes und der Unfähigkeit, andere Aufgaben als die, die ihnen angegeben sind, zu erfüllen, werden sie auch als „schwache“ KI bezeichnet. Dies macht ihre Intelligenz hoch auf eine Aufgabe oder Aufgaben fokussiert, was eine weitere Optimierung und Optimierung ermöglicht.
Warum wird es Narrow Intelligence genannt?
Narrow AI ist für bestimmte Aufgaben ausgelegt und kann keine anderen Aufgaben ausführen als die, die ihm angegeben sind. Dieser enge Fokus ist vor allem auf folgende Faktoren zurückzuführen:
- Narrow AI ist ein komplexes Computerprogramm
Schmale KI ist in der Regel in ihrem Umfang eingeschränkt, weil sie geschaffen wird, um ein Problem zu lösen. Es wird mit dem expliziten Fokus aufgebaut, um sicherzustellen, dass eine Aufgabe erledigt wird, wobei seine Architektur und Funktionsweise dies darstellen.
Die heutige enge KI besteht nicht aus nicht quantifizierbaren Teilen; es ist nur ein Computerprogramm, das gemäß den Anweisungen, die ihm gegeben werden, ausgeführt wird. Aufgrund dieser Einschränkungen und des angegebenen Einsatzkoffers hat enge KI einen Laserfokus auf die Aufgaben, für die sie geschaffen wurde.
- Schmale KI wird nach heutigen Standards und Tools erstellt
Mit der Zunahme der Einführung von KI durch Unternehmen wird erwartet, dass die Technologie eine Sache tut und es gut macht. Während sich der Gebrauchskoffer von Unternehmen zu Unternehmen unterscheiden könnte, sind die Erwartungen gleich – ein exponentieller Anstieg des Endergebnisses. Heute kann dies nur mit schmaler KI geschehen. Schmale KI wird in einem Umfeld entwickelt, in dem das Problem mit modernster Technologie im Vordergrund steht. Künstliche Intelligenz ist im Allgemeinen ein hochforschungsorientiertes Feld, und die Forschungsgrundarbeit, um etwas mehr als ein einzelnes Einsatzsystem zu schaffen, wurde noch nicht festgelegt. Das schafft KI mit einem engen Fokus.
Dank seiner hohen Effizienz, Geschwindigkeit und Verbrauchsrate gegenüber dem Menschen ist eine enge künstliche Intelligenz eine der wichtigsten Lösungen für Unternehmen. Für eine Vielzahl von Low-Level-Aufgaben kann enge KI intelligente Automatisierung und Integration einsetzen, um Effizienz bei gleichzeitiger Aufrechterhaltung der Genauigkeit zu gewährleisten.
Dies macht es zu einer bevorzugten Wahl für Aufgaben, die Millionen von Datenmengen beinhalten, die als Big Data bekannt sind. Da die persönliche Datenerhebung vorherrscht, verfügen Unternehmen über eine große Menge an Big Data, die für die Ausbildung von KI und das Ableiten von Erkenntnissen verwendet werden kann.
Beispiele für Narrow AI sind:
- Empfehlung
Wann immer Sie ein “empfohlenes” Tag auf einer Website sehen, wird es normalerweise von einer engen KI dorthin gebracht. Durch das Anschauen der Präferenzen eines Benutzers in Bezug auf die Datenbank von Inhalten oder Informationen ist eine KI in der Lage, ihre Vorlieben und Abneigungen zu bestimmen.
Dies wird dann verwendet, um Empfehlungen zu geben, die dem Benutzer ein persönlicheres Erlebnis bieten. Dies wird häufig auf Seiten wie Netflix („Weil Sie gesehen haben…“), YouTube („Recommended“), Twitter („Top Tweets first“) und viele weitere Dienste gesehen. - Spamfilterung
Schmale KI mit natürlichen Sprachverarbeitungsfunktionen wird eingesetzt, um unsere Posteingänge sauber zu halten. Mitarbeiter können nicht jede Spam-E-Mail überprüfen, die sie erhalten, aber es ist eine perfekte Aufgabe für enge KI.
Google ist führend bei der Bereitstellung von E-Mail-Diensten und hat seine enge KI bis zu einem Punkt weiterentwickelt, an dem es verschiedene E-Mail-bezogene Aufgaben erledigt. Zusammen mit KI-gestützten Spam-Filtern können sie auch eine Kategorie einer bestimmten Art von E-Mail zuordnen (Promotions, Erinnerungen, wichtig usw.). - Expertensysteme
Narrow AI hat die Fähigkeit, Expertensysteme zu schaffen, die den Weg für die Zukunft der KI ebnen könnten. So wie die menschliche Intelligenz aus verschiedenen Sinnen und logischen, kreativen und kognitiven Aufgaben besteht; Expertensysteme bestehen auch aus vielen Teilen.
Expertensysteme können die Zukunft der künstlichen Intelligenz darstellen. Dieser Begriff wird verwendet, um ein KI-System zu bezeichnen, das aus vielen kleineren schmalen KI-Algorithmen besteht. Zum Beispiel besteht IBM Watson aus einer natürlichen Sprachverarbeitungskomponente zusammen mit einem kognitiven Aspekt. - Kampf DrohnenEnge KI-fähige autonome Kampfd Drohnen werden derzeit in der Ukraine entwickelt, getestet und eingesetzt.
Künstliche Intelligenz (AGI)
Während sich schmale KI darauf bezieht, wohin künstliche Intelligenz heute gelangt ist, bezieht sich die allgemeine KI darauf, wo sie in Zukunft sein wird. Auch bekannt als künstliche allgemeine Intelligenz (AGI) und starke KI, ist allgemeine künstliche Intelligenz eine Art von KI, die mehr wie Menschen denken und funktionieren kann. Dazu gehören Wahrnehmungsaufgaben wie Vision und Sprachverarbeitung sowie kognitive Aufgaben wie Verarbeitung, Kontextverständnis, Denken und ein allgemeinerer Ansatz für das Denken.
Während schmale KI als Mittel zur Ausführung einer bestimmten Aufgabe geschaffen wird, kann AGI breit und anpassungsfähig sein. Der Lernteil der adaptiven allgemeinen Intelligenz muss auch unbeaufsichtigt sein, im Gegensatz zum überwachten und bezeichneten Lernen, das heute eine schmale KI durchgesetzt wird.
Werkzeuge, die für den Bau von AGI erforderlich sind, sind heute nicht verfügbar. Viele argumentieren, dass neuronale Netzwerke eine zuverlässige Möglichkeit sind, die Vorläufer dessen zu schaffen, was künstliche allgemeine Intelligenz genannt werden kann, aber menschliche Intelligenz ist immer noch eine Blackbox. Es gibt eine Schule des Denkens, dass AGI in den nächsten drei Jahren erreicht wird, und einige glauben, dass eine teilweise AGI bereits in einigen Unternehmen existieren könnte, die versuchen, AGI für kommerzielle Zwecke zu entwickeln.
Während die Menschen beginnen, das Innenleben unseres Geistes und Gehirns zu entschlüsseln, sind wir noch weit davon entfernt, herauszufinden, was “Intelligenz” bedeutet. Zusätzlich zu diesem Hindernis ist die Notwendigkeit, “Geständigtheit” zu definieren, integraler Bestandteil der Schaffung einer allgemeinen KI. Das liegt daran, dass ein AGI „bewusst“ sein muss und nicht nur ein Algorithmus oder eine Maschine.
Das Unternehmen Elon Musk, Tesla, entwickelt derzeit einen Mehrzweckroboter (Tesla Optimus), der für allgemeine Verbraucher gedacht ist und schließlich AGI-Funktionen an Bord integrieren kann. Stellen Sie sich einen Heimroboter mit einem Äquivalent von hundert Doktortiteln vor. Der erwartete Verkaufspreis liegt bei etwa 20.000 US-Dollar.
Künstliche Super Intelligenz
Künstliche Superintelligenz (ASI) ist ein Begriff, der verwendet wird, um eine KI zu bezeichnen, die die menschliche Kognition auf jede erdeng. Dies ist eine der weit entferntesten Theorien der künstlichen Intelligenz, aber es wird im Allgemeinen als das letztendliche Endspiel der Schaffung einer KI angesehen.
Während künstliche Superintelligenz zu diesem Zeitpunkt noch eine Theorie ist, wurden viele Szenarien, die es beinhalten, bereits vorgestellt. Ein gemeinsamer Konsens unter den Unternehmen ist, dass ASI aus dem exponentiellen Wachstum von KI-Algorithmen, auch bekannt als “Intelligence Explosion”, kommen wird.
Die Explosion der Intelligenz ist ein Konzept, das für die Schaffung künstlicher Superintelligenz erforderlich ist. Wie der Name schon sagt, ist es eine Explosion der Intelligenz von der allgemeinen künstlichen Intelligenz auf menschlicher Ebene und einem undenkbaren Niveau. Dies wird durch rekursive Selbstverbesserung (Selbstlernen) erwartet.
Die Selbstverbesserung in der KI erfolgt in Form des Lernens aus Benutzereingaben in neuronalen Netzwerken. Die wiedererlangende Selbstverbesserung ist dagegen die Fähigkeit eines KI-Systems, von sich selbst zu lernen, bei schnell steigenden Ebenen zunehmender Intelligenz.
Um dies zu veranschaulichen, sollten Sie eine AGI in Betracht ziehen, die auf der Ebene der durchschnittlichen menschlichen Intelligenz funktioniert. Es wird von sich selbst lernen, indem es die kognitiven Fähigkeiten eines durchschnittlichen Menschen nutzt, um Intelligenz auf Genie-Niveau zu erreichen. Dies beginnt jedoch, sich zu verzMingung zu verzMacht zu entwickeln, und jedes zukünftige Lernen, das von der KI gemacht wird, wird auf genialer kognitiver Funktion durchgeführt.
Dies beschleunigt sich in einem schnellen Tempo und schafft eine Intelligenz, die bei jedem Schritt klüger ist als sie selbst. Dies baut sich weiter schnell auf, bis der Punkt, an dem Intelligenz explodiert und eine Superintelligenz geboren wird.
Viele Führungspersönlichkeiten in diesem Bereich gehen davon aus, dass sich, sobald eine selbsternannte, fähige AGI geschaffen ist, innerhalb von Monaten zu einem ASI werden.
Was sind die Risiken der Künstlichen Intelligenz?
Das Massachusetts Institute of Technology (MIT) Computer Science & Artificial Intelligence Laboratory (CSAIL) hat kürzlich die weltweit erste umfassende Datenbank entwickelt, die sich der Katalogisierung der verschiedenen Risiken im Zusammenhang mit künstlicher Intelligenz widmet, und hat diese Ressource der Öffentlichkeit zugänglich gemacht. Diese neue Ressource, bekannt als AI Risk Repository, ist das Ergebnis einer kollaborativen internationalen Anstrengung, die verschiedenen Möglichkeiten zu katalogisieren, wie KI-Technologien Probleme schaffen können, was sie zu einem wichtigen Projekt für politische Entscheidungsträger, Forscher, Ethiker, Entwickler, IT-Profis und die breite Öffentlichkeit macht.
Die neue Datenbank kategorisiert 700 verschiedene Risiken, die von technischen Fehlern über Cybersicherheitsanfälligkeiten bis hin zu ethischen Bedenken und anderen Auswirkungen auf die Gesellschaft reichen. Bisher stand keine zentralisierte Ressource zur Verfügung, um die mit diesen Technologien verbundenen Risiken aufzulisten und zu kategorisieren. Derzeit gibt es keine anerkannte Autorität, Think Tank oder Governance-Struktur, die sich der Bewertung dieser Risiken und der Bereitstellung von Regeln oder Anleitungen dafür widmet, wie Unternehmen oder andere interessierte Parteien diese Risiken umgehen sollten. Diese Situation ist sehr ähnlich wie in den frühen Tagen der Atomenergie, der rekombinanten DNA oder der infektienten Krankheitserreger-Wirkungsforschung.
Das AI Risk Repository hat drei Teile:
- Die AI Risk Database erfasst mehr als 700 Risiken, die aus 43 bestehenden Frameworks mit Zitaten und Seitenzahlen extrahiert werden.
- Die kausale Taxonomie der KI-Risiken stuft ein, wie, wann und warum diese Risiken auftreten.
- Die Domain Taxonomie von KI-Risiken klassifiziert diese Risiken in sieben Domains (z. B. „Fehlinformationen“) und 23 Subdomains (z. B. „Fale oder irreführende Informationen“).
Die Domain Taxonomie von KI-Risiken klassifiziert Risiken von KI in sieben Domains und 23 Subdomains.

Das Team, das diese neue Ressource entwickelt hat, hat ihre Arbeit in einer kurzen Zusammenfassung zusammengefasst, die für ein allgemeines Publikum geschrieben wurde.
- Die Risiken der Künstlichen Intelligenz (KI) betreffen viele Akteure
- Viele Forscher haben versucht, diese Risiken zu klassifizieren
- Bestehende Klassifikationen sind unkoordiniert und inkonsistent
- Wir überprüfen und synthetisieren vorherige Klassifikationen, um ein KI-Risiko-Repository zu produzieren, einschließlich eines Papiers, einer ursätzalen Taxonomie, der Domain-Taxonomie, der Datenbank und der Website
- Nach unserem Wissen ist dies der erste Versuch, KI-Risiko-Frameworks rigoros in eine öffentlich zugängliche, umfassende, erweiterbare und kategorisierte Risikodatenbank zu kuratieren, zu analysieren und zu entwickeln.
Die Risiken, die von Artificial Intelligence (AI) ausgehen, sind für eine Vielzahl von Interessengruppen, darunter politische Entscheidungsträger, Experten, KI-Unternehmen und die Öffentlichkeit, von großem Interesse. Diese Risiken erstrecken sich über verschiedene Bereiche und können sich auf unterschiedliche Weise manifestieren: Die AI Incident Database umfasst jetzt über 3.000 reale Fälle, in denen KI-Systeme Schaden angerichtet oder fast verursacht haben.
Um einen klareren Überblick über diese komplexe Reihe von Risiken zu schaffen, haben viele Forscher versucht, sie zu identifizieren und zu gruppieren. Theoretisch sollten diese Bemühungen helfen, die Komplexität zu vereinfachen, Muster zu identifizieren, Lücken hervorzuheben und eine effektive Kommunikation und Risikoprävention zu ermöglichen. In der Praxis waren diese Bemühungen oft unkoordiniert und vielfältig in ihrem Umfang und Fokus, was zu zahlreichen widersprüchlichen Klassifikationssystemen führte. Selbst wenn verschiedene Klassifikationssysteme ähnliche Begriffe für Risiken (z. B. „Privatsphäre“) verwenden oder sich auf ähnliche Domains (z.B. „existentielle Risiken“) konzentrieren, können sie sich inkonsistent auf Konzepte beziehen. Infolgedessen ist es immer noch schwer, das volle Ausmaß des KI-Risikos zu verstehen. In dieser Arbeit bauen wir auf früheren Bemühungen auf, KI-Risiken zu klassifizieren, indem wir ihre vielfältigen Perspektiven zu einem umfassenden, einheitlichen Klassifizierungssystem kombinieren.
Während dieses Syntheseprozesses erkannten wir, dass unsere Ergebnisse zwei Arten von Klassifikationssystemen enthielten:
- Hochrangige Kategorisierungen der Ursachen von KI-Risiken (z. B. wann oder warum Risiken durch KI auftreten)
- Gefahren oder Schäden durch KI auf mittlerer Ebene (z. B. KI wird nach begrenzten Daten geschult oder zur Herstellung von Waffen verwendet)
Da diese Klassifikationssysteme so unterschiedlich waren, war es schwer, sie zu verengen; Risikokategorien wie „Diffusion der Verantwortung“ oder „Menschen schaffen gefährliche KI aus Versehen“ nicht auf engere Kategorien wie „Missuse“ oder „Noisy Training Data“ oder umgekehrt. Wir haben daher beschlossen, zwei verschiedene Klassifikationssysteme zu schaffen, die gemeinsam unser einheitliches Klassifikationssystem bilden würden. Das Papier, das wir produziert haben, und seine assoziierten Produkte (d. h. causal Taxonomy, Domain Taxonomie, Wohndatenbank und Website) bietet eine klare, zugängliche Ressource, um ein umfassendes Spektrum an Risiken im Zusammenhang mit KI zu verstehen und zu adressieren. Wir bezeichnen diese Produkte als AI Risk Repository.
Die kurze Tabelle (unten), die die Ergebnisse des Teams durch Domain Taxonomy zusammenfasst, gibt einen bequemen Überblick über das aktuelle Denken hinsichtlich der Risiken, die mit künstlicher Intelligenz verbunden sind.


Wie oben erwähnt, gibt es derzeit keine nationale oder internationale Einrichtung oder Struktur, die mit der Internationalen Atomenergiebehörde vergleichbar ist, um diese Risiken zu bewerten oder Leitlinien zu geben und zu geben, wie sie verwaltet und gemildert werden sollten. Die in den USA ansässige Union of Concerned Scientists (UCS) beginnt, Fragen der KI-Entwicklung und Sicherheitsrisiken hervorzuheben.
Am 30. Oktober 2023 erließ das Weiße Haus eine neue Verfügung über den Einsatz von künstlicher Intelligenz (KI)-Technologie, die Richtlinien zum Schutz von Sicherheit, Privatsphäre, Gerechtigkeit und den Rechten von Verbrauchern, Patienten und Arbeitern vorlegte.
Als Antwort, Dr. Jennifer Jones, Direktorin des Center for Science and Democracy bei der UCS, gab folgende Erklärung ab:
„Künstliche Intelligenztechnologien haben echtes Potenzial, die Art und Weise, wie wir unser Leben führen, zu verändern – aber wir können nicht einfach davon ausgehen, dass sie zum öffentlichen Nutzen arbeiten werden. Diese Technologien sind konsequent und kommen mit realen Risiken, und wir müssen unsere eigene Intelligenz einsetzen, um sicherzustellen, dass wir die Risiken managen. Diese Bemühungen erfordern eine Zusammenarbeit zwischen Regierungen, Unternehmen, Wissenschaftlern und Gemeindeorganisationen.
„Die KI-Technologie ist rasant gewachsen, wirft aber wichtige Fragen auf. Wie werden wir sicherstellen, dass Menschen genaue und zuverlässige Informationen aus dem Meer von KI-generierten Inhalten erhalten? Wie stellen wir sicher, dass KI-Systeme nicht darauf ausgelegt sind, die Rassen-, Geschlechter- und Klassenverzerrungen zu replizieren, die zu Diskriminierung und Unterdrückung führen? Können wir sicherstellen, dass KI-Tools nicht nur zu einer weiteren Quelle von Desinformation und Möglichkeiten zur Ausbeutung durch schlechte Akteure werden? Wie werden KI-generierte Informationen in der Entscheidungsfindung der Regierung verwendet?
„Dieser exekutive Auftrag ist ein guter erster Schritt, der sich mit einigen – aber nicht nur der lebenswichtigen Fragen zur KI-Technologie befasst. Es hat eine solide Sprache im Zusammenhang mit dem Schutz der Privatsphäre und schaut auf mehrere Probleme, die sich mit KI kreuzen. Eine breitere Reihe von KI-Leitlinien sollte Bemühungen zum Schutz vor Desinformation, zur sicheren Technologiesicherheit, zur Verteidigung freier und fairer Wahlen und zur Koordinierung mit den Gemeinden und Gruppen gehören, die am wahrscheinlichsten von KI betroffen sind. Darüber hinaus sollte das Büro für Wissenschaft und Technologiepolitik des Weißen Hauses einen Bericht über die Beziehung zwischen KI-Technologie und wissenschaftlicher Integrität prüfen und herausgeben.
„Wir müssen durchdachte, absichtliche Entscheidungen darüber treffen, wie wir Technologien einsetzen – Entscheidungen, die sich um Menschen zentrieren, nicht um die Technologien selbst. Die heutige Exekutivanordnung ist ein Schritt in die richtige Richtung, aber mehr Arbeit an diesem Thema wird sicherlich erforderlich sein. Wir werden genau beobachten, ob die Bundesregierung eine effektive und umfassende Anleitung zum Einsatz von KI-Technologien bietet.“
Fazit
Künstliche Intelligenz (KI) und die Schnittstellen zwischen KI, Robotik-Technologie und Technologie, die eine direkte Verbindung zwischen menschlichen Gehirnen und Computersystemen und Netzwerken ermöglichen, werden unsere Welt auf unzählige Arten stören, die wir nur zu antizipieren beginnen. Dieses Wissen und Können wird für eine Vielzahl kommerzieller und politischer Interessen weiter genutzt und wird die Welt, in der wir leben, herausfordern und verändern. Es ist schwer vorstellbar, ob es angesichts des fragmentierten, multilateralen Charakters der aktuellen globalen politischen Strukturen überhaupt möglich sein wird, die vielen damit verbundenen Risiken zu regulieren und zu mindern. Doch die Lehren aus jüngster Vergangenheit zeigen, dass die Einführung globaler Governance-Strukturen auf diese Technologie den globalen Korporatismus und den Totalitarismus weiter vorantreiben wird.
Das Weltwirtschaftsforum (WEF) fördert eine transhumanistische Agenda, die zum Teil auf futuristischen Projektionen zu Robotik und künstlicher Intelligenz basiert, insbesondere durch seine Initiative „Great Reset“. Diese Vision stellt sich eine Zukunft vor, in der die Menschheit durch Technologie erweitert und verändert wird, was zu einer neuen Ära der menschlichen Evolution führt.
Schlüsselpunkte:
- The Great Reset : Der Plan des WEF für eine Welt nach dem Coronavirus, die die Innovationen der Vierten Industriellen Revolution zur Unterstützung des öffentlichen Wohls nutzt. Dazu gehört die Integration von Technologien, die das, was es bedeutet, Mensch zu sein, verändern wird, wie Gehirn-Computer-Schnittstellen, Nanotechnologie und synthetische Biologie.
- Transhumanistische Ziele : Die transhumanistische Vision des WEF zielt darauf ab, menschliche Grenzen, einschließlich Altern, Krankheit und Tod, durch technologischen Fortschritt zu überwinden. Dazu gehören:
- Unsterblichkeit durch Nanoroboter, Gentechnik und digitales Gehirn-Reding.
- Permanentes Glück durch „Glücksmedikamente“ und Hirnchips-Schnittstellen.
- Menschen werden zu „godartigen“ Schöpfern, die in der Lage sind, die materielle Welt zu manipulieren und neue Lebensformen zu schaffen.
- Dataism : Yuval Noah Harari, ein wichtiger Berater des WEF, schlägt eine „Datenreligion“ vor, in der Daten (Informationsverarbeitung) Gott oder die menschliche Natur als ultimative Quelle von Bedeutung und Autorität ersetzen. In dieser Zukunft würde uns eine sich selbst verbessernde superintelligente KI besser kennen, als wir uns selbst kennen und als eine Art allwissendes Orakel oder Souveräns funktionieren.
- Ethische Anliegen: Die transhumanistische Agenda des WEF wirft ethische Fragen über die Grenzen der menschlichen Verbesserung, das Potenzial für Autoritarismus und die Auswirkungen auf Demokratie und individuelle Freiheit auf.
Bemerkenswerte Relevante WEF-Zitate:
- „Diese digitale Identität bestimmt, auf welche Produkte, Dienstleistungen und Informationen wir zugreifen können – oder umgekehrt, was uns verschlossen ist.“ – Weltwirtschaftsforum 2018
- „Autoritarismus ist in einer Welt der totalen Sichtbarkeit und Rückverfolgbarkeit einfacher, während sich die Demokratie als schwieriger herausstellt.“ – Weltwirtschaftsforum 2019
Wer Robert Malone ist eine Leser-unterstützte Publikation. Um neue Beiträge zu erhalten und meine Arbeit zu unterstützen, sollten Sie einen kostenlosen oder bezahlten Abonnenten werden.
Danke für die Lektüre Who ist Robert Malone! Dieser Beitrag ist öffentlich, also fühlen Sie sich frei, ihn zu teilen.
Dieser Beitrag sind nicht die Äußerungen der Basistreff AG Company, Limited by guarantee. Es sind die Worte von Robert Malone, erstmalig in englisch veröffentlicht am 26. August 2024 auf Substack. Der Beitrag wurde von uns lediglich in die deutsche Sprache übersetzt und Dir im gesetzlich gesicherten Rahmen der freien Zugänglichkeit von Informationen 1:1, unkommentiert und ungeprüft für Dich zur Verfügung gestellt.
HIer der Link zum Original Beitrag von Robert Malone on Substack.


